
Repository Summary
| Description | grep for ROS bag files and live topics |
| Checkout URI | https://github.com/suurjaak/grepros.git |
| VCS Type | git |
| VCS Version | master |
| Last Updated | 2024-05-06 |
| Dev Status | DEVELOPED |
| CI status | No Continuous Integration |
| Released | RELEASED |
| Tags | No category tags. |
| Contributing |
Help Wanted (0)
Good First Issues (0) Pull Requests to Review (0) |
Packages
| Name | Version |
|---|---|
| grepros | 1.2.2 |
README
grepros
grep for ROS bag files and live topics: read, filter, export.
Searches through ROS messages and matches any message field value by regular expression patterns or plain text, regardless of field type. Can also look for specific values in specific message fields only.
By default, matches are printed to console. Additionally, matches can be written to a bagfile or HTML/CSV/MCAP/Parquet/Postgres/SQL/SQLite, or published to live topics.
Supports both ROS1 and ROS2. ROS environment variables need to be set, at least ROS_VERSION.
Supported bag formats: .bag (ROS1), .db3 (ROS2), .mcap (ROS1, ROS2).
In ROS1, messages can be grepped even if Python packages for message types are not installed. Using ROS1 live topics requires ROS master to be running.
Using ROS2 requires Python packages for message types to be available in path.
Supports loading custom plugins, mainly for additional output formats.
Usable as a Python library, see LIBRARY.md. Full API documentation available at https://suurjaak.github.io/grepros.
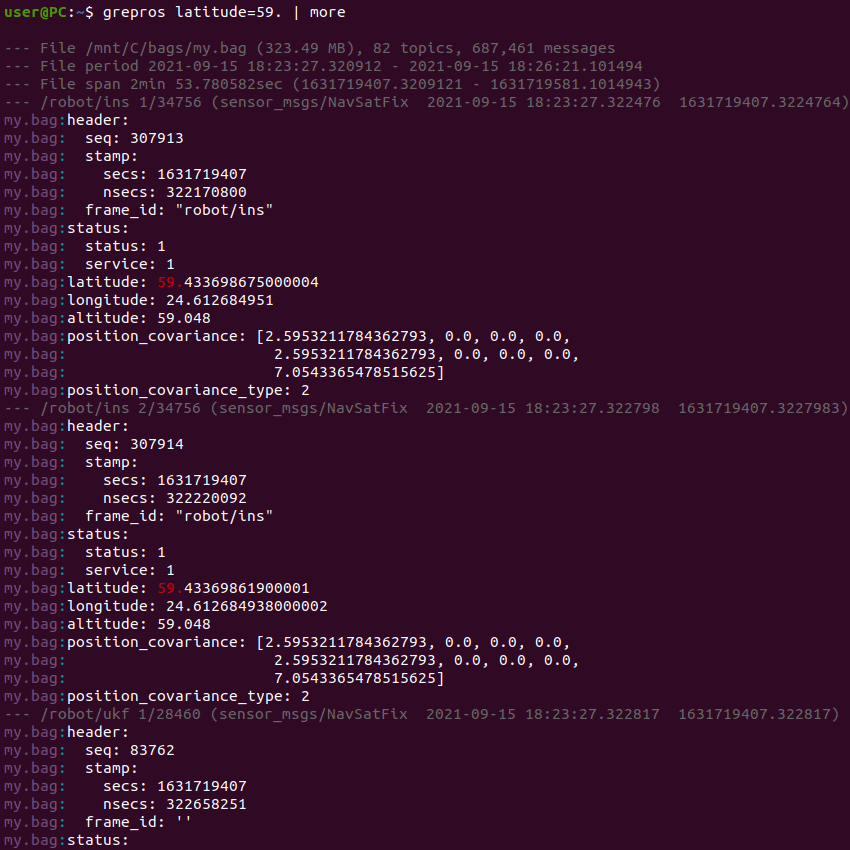
- Example usage
- Installation
- Inputs
- Outputs
- Matching and filtering
- Plugins
- Notes on ROS1 vs ROS2
- All command-line arguments
- Dependencies
- Attribution
- License
Example usage
Search for “my text” in all bags under current directory and subdirectories:
grepros -r "my text"
Print 30 lines of the first message from each live ROS topic:
grepros --max-per-topic 1 --lines-per-message 30 --live
Find first message containing “future” (case-sensitive) in my.bag:
grepros future -I --max-count 1 --name my.bag
Find 10 messages, from geometry_msgs package, in “map” frame, from bags in current directory, reindexing any unindexed bags:
grepros frame_id=map --type geometry_msgs/* --max-count 10 --reindex-if-unindexed
Pipe all diagnostics messages with “CPU usage” from live ROS topics to my.bag:
grepros "CPU usage" --type *DiagnosticArray --no-console-output --write my.bag
Find messages with field “key” containing “0xA002”, in topics ending with “diagnostics”, in bags under “/tmp”:
grepros key=0xA002 --topic *diagnostics --path /tmp
Find diagnostics_msgs messages in bags in current directory, containing “navigation” in fields “name” or “message”, print only header stamp and values:
grepros --type diagnostic_msgs/* --select-field name message \
--emit-field header.stamp status.values -- navigation
Print first message from each lidar topic on ROS1 host 1.2.3.4, without highlight:
ROS_MASTER_URI=http://1.2.3.4::11311 \
grepros --live --topic *lidar* --max-per-topic 1 --no-highlight
Export all bag messages to SQLite and Postgres, print only export progress:
grepros -n my.bag --write my.bag.sqlite --no-console-output --no-verbose --progress
grepros -n my.bag --write postgresql://user@host/dbname \
--no-console-output --no-verbose --progress
Patterns use Python regular expression syntax, message matches if all match. ‘*’ wildcards use simple globbing as zero or more characters, target matches if any value matches.
Note that some expressions may need to be quoted to avoid shell auto-unescaping
or auto-expanding them, e.g. linear.x=2.?5 should be given as "linear.x=2\.?5".
Care must also be taken with unquoted wildcards, as they will auto-expanded by shell if they happen to match paths on disk.
Installation
grepros is written in Python, supporting both Python 2 and Python 3.
Developed and tested under ROS1 Noetic and ROS2 Foxy, works in later ROS2 versions (Galactic, Humble, Iron, and likewise Rolling); also works in the earlier ROS1 version Melodic (lacking MCAP and Parquet support).
Using pip
pip install grepros
This will add the grepros command to path.
Requires ROS Python packages (ROS1: rospy, roslib, rosbag, genpy; ROS2: rclpy, rosidl_parser, rosidl_runtime_py, builtin_interfaces).
For ROS1, if only using bag files and no live topics, minimal ROS1 Python packages can also be installed separately with:
pip install rospy rosbag roslib roslz4 \
--extra-index-url https://rospypi.github.io/simple/
Using apt
If ROS apt repository has been added to system:
sudo apt install ros-noetic-grepros # ROS1 Noetic
sudo apt install ros-foxy-grepros # ROS2 Foxy
This will add the grepros command to the global ROS1 / ROS2 environment.
Using catkin
In a ROS1 workspace, under the source directory:
git clone https://github.com/suurjaak/grepros.git
cd grepros
catkin build --this
This will add the grepros command to the local ROS1 workspace path.
Using colcon
In a ROS2 workspace, at the workspace root:
git clone https://github.com/suurjaak/grepros.git src/grepros
colcon build --packages-select grepros
This will add the grepros command to the local ROS2 workspace path.
Inputs
Input is either from one or more ROS bag files (default), or from live ROS topics.
bag
Read messages from ROS bag files, by default all in current directory.
For reading bags in MCAP format, see the MCAP plugin.
Recurse into subdirectories when looking for bagfiles:
-r
--recursive
Read specific filenames (supports * wildcards):
--n /tmp/*.bag
--filename my.bag 2021-11-*.bag
Scan specific paths instead of current directory (supports * wildcards):
-p /home/bags/2021-11-*
--path my/dir
Emit messages on original bag timeline from first matched message, optionally with a speedup or slowdown factor:
--time-scale # At original rate
--time-scale 2 # Twice faster
--time-scale 0.5 # Twice slower
Reindex unindexed ROS1 bags before processing (note: creates backup copies of files, into same directory as file):
--reindex-if-unindexed
--reindex-if-unindexed --progress
Decompress archived ROS bags before processing
(.zst .zstd extensions, requires zstandard Python package)
(note: unpacks archived file to disk, into same directory as file):
--decompress
--decompress --progress
Order bag messages first by topic or type, and only then by time:
--order-bag-by topic
--order-bag-by type
live
--live
Read messages from live ROS topics instead of bagfiles.
Requires ROS_MASTER_URI and ROS_ROOT to be set in environment if ROS1.
Set custom queue size for subscribing (default 10):
--queue-size-in 100
Use ROS time instead of system time for incoming message timestamps:
--ros-time-in
Outputs
There can be any number of outputs: printing to console (default), publishing to live ROS topics, or writing to file or database.
console
Default output is to console, in ANSI colors, mimicking grep output.
Disable printing messages to console:
--no-console-output
Manage color output:
--color always (default)
--color auto (auto-detect terminal support)
--color never (disable colors)
Note that when paging color output with more or less, the pager needs to
accept raw control characters (more -f or less -R).
bag
--write path/to/my.bag [format=bag] [overwrite=true|false]
[rollover-size=NUM] [rollover-count=NUM] [rollover-duration=NUM]
[rollover-template=STR]
Write messages to a ROS bag file, the custom .bag format in ROS1,
or the .db3 SQLite database format in ROS2. If the bagfile already exists,
it is appended to, unless specified to overwrite.
Specifying format=bag is not required
if the filename ends with .bag in ROS1 or .db3 in ROS2.
For writing bags in MCAP format, see the MCAP plugin.
More on rollover.
live
--publish
Publish messages to live ROS topics. Topic prefix and suffix can be changed, or topic name set to one specific name:
--publish-prefix /myroot
--publish-suffix /myend
--publish-fixname /my/singular/name
One of the above arguments needs to be specified if publishing to live ROS topics while grepping from live ROS topics, to avoid endless loops.
Set custom queue size for publishers (default 10):
--queue-size-out 100
csv
--write path/to/my.csv [format=csv] [overwrite=true|false]
Write messages to CSV files, each topic to a separate file, named
path/to/my.full__topic__name.csv for /full/topic/name.
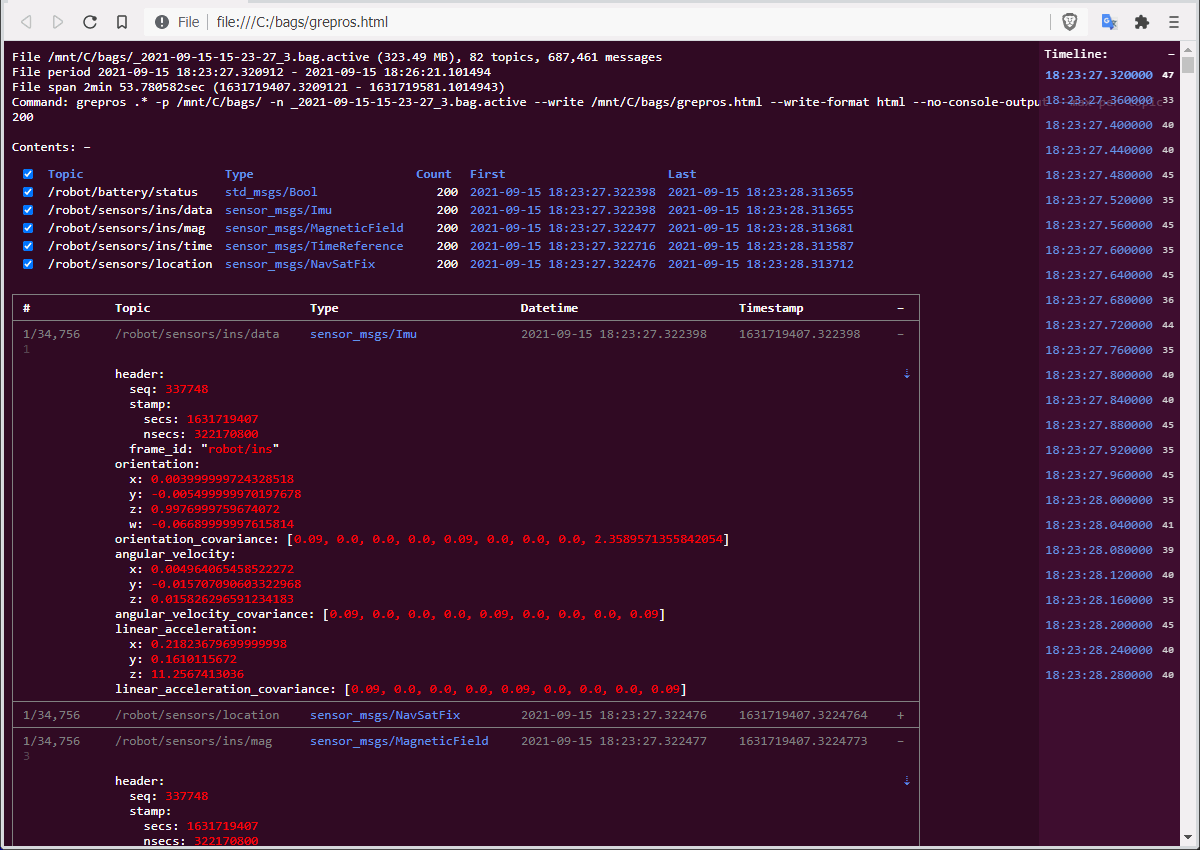
html
--write path/to/my.html [format=html] [overwrite=true|false]
[template=/path/to/html.template]
[rollover-size=NUM] [rollover-count=NUM] [rollover-duration=NUM]
[rollover-template=STR]
Write messages to an HTML file, with a linked table of contents, message timeline, message type definitions, and a topically traversable message list.
More on rollover.
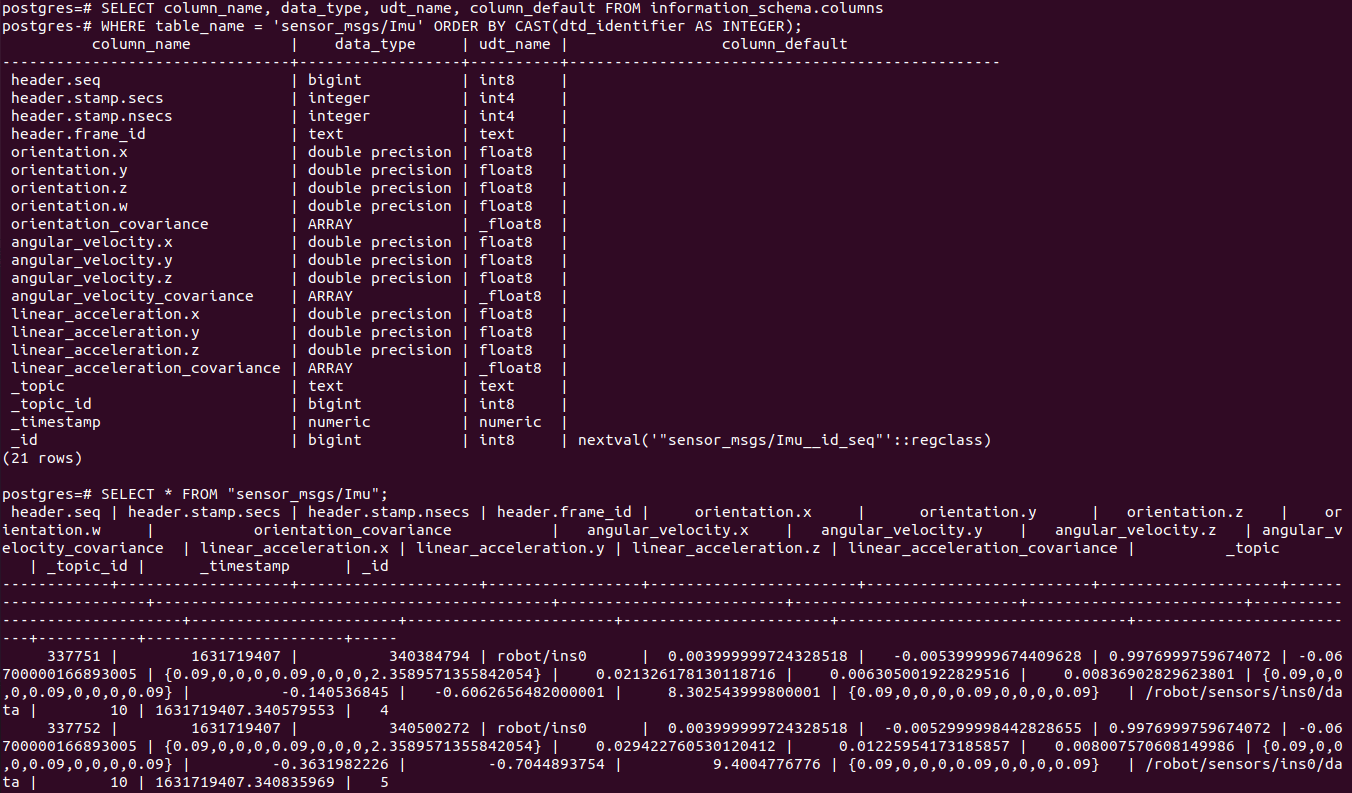
postgres
--write postgresql://username@host/dbname [format=postgres]
[commit-interval=NUM] [nesting=array|all]
[dialect-file=path/to/dialects.yaml]
Write messages to a Postgres database, with tables pkg/MsgType for each ROS message type,
and views /full/topic/name for each topic.
sqlite
--write path/to/my.sqlite [format=sqlite] [overwrite=true|false]
[commit-interval=NUM] [message-yaml=true|false] [nesting=array|all]
[dialect-file=path/to/dialects.yaml]
[rollover-size=NUM] [rollover-count=NUM] [rollover-duration=NUM]
[rollover-template=STR]
Write an SQLite database with tables pkg/MsgType for each ROS message type
and nested type, and views /full/topic/name for each topic.

More on outputs in doc/DETAIL.md.
console / html message formatting
Set maximum number of lines to output per message:
--lines-per-message 5
Set maximum number of lines to output per message field:
--lines-per-field 2
Start message output from, or stop output at, message line number:
--start-line 2 # (1-based if positive
--end-line -2 # (count back from total if negative)
Output only the fields where patterns find a match:
--matched-fields-only
Output only matched fields and specified number of lines around match:
--lines-around-match 5
Output only specific message fields (supports nested.paths and * wildcards):
--emit-field *data
Skip outputting specific message fields (supports nested.paths and * wildcards):
--no-emit-field header.stamp
Wrap matches in custom texts:
--match-wrapper @@@
--match-wrapper "<<<<" ">>>>"
Set custom width for wrapping message YAML printed to console (auto-detected from terminal by default):
--wrap-width 120
Matching and filtering
Any number of patterns can be specified, message matches if all patterns find a match. If no patterns are given, any message matches.
Match messages containing all of the words:
cpu memory speed
Match messages where frame_id contains “world”:
frame_id=world
Match messages where header.frame_id is present:
header.frame_id=.*
Match as plaintext, not Python regular expression patterns:
-F
--fixed-strings
Select non-matching messages instead:
-v
--invert-match
Use case-sensitive matching in patterns (default is insensitive):
-I
--no-ignore-case
Give pattern as a logical expression like this AND (this2 OR NOT "skip this"),
with elements as patterns to find in message fields:
-e
--expression
# (Match live messages containing 'cpu' or 'memory')
cpu OR memory --expression --live
Limits
Stop after matching a specified number of messages (per each file if bag input):
-m 100
--max-count 100
Read only a specified number of topics (per each file if bag input):
--max-topics 10
Emit a specified number of matches per topic (per each file if bag input):
--max-per-topic 20
Emit every Nth match in topic, starting from first:
--every-nth-match 10 # (emits matches #1 #11 #21 ..)
Filtering
Read specific topics only (supports * wildcards):
-t *lidar* *ins*
--topic /robot/sensors/*
Skip specific topics (supports * wildcards):
-nt *lidar* *ins*
--no-topic /robot/sensors/*
Read specific message types only (supports * wildcards):
-d *Twist*
--type sensor_msgs/*
Skip specific message types from reading (supports * wildcards):
-nd *Twist*
--no-type sensor_msgs/*
Set specific message fields to scan (supports nested.paths and * wildcards):
-sf twist.linear
--select-field *data
Skip specific message fields in scan (supports nested.paths and * wildcards):
-ns twist.linear
--no-select-field *data
Only emit matches that are unique in topic,
taking --select-field and --no-select-field into account (per each file if bag input):
--unique-only
Start reading from a specific timestamp:
-t0 2021-11 # (using partial ISO datetime)
--start-time 1636900000 # (using UNIX timestamp)
--start-time +100 # (seconds from bag start time, or from script startup time if live input)
--start-time -100 # (seconds from bag end time, or script startup time if live input)
Stop reading at a specific timestamp:
-t1 2021-11 # (using partial ISO datetime)
--end-time 1636900000 # (using UNIX timestamp)
--end-time +100 # (seconds from bag start time, or from script startup time if live input)
--end-time -100 # (seconds from bag end time, or from script startup time if live input)
Start reading from a specific message index in topic:
-n0 -100 # (counts back from topic total message count in bag)
--start-index 10 # (1-based index)
Stop reading at a specific message index in topic:
-n1 -100 # (counts back from topic total message count in bag)
--end-index 10 # (1-based index)
Read every Nth message in topic, starting from first:
--every-nth-message 10 # (reads messages #1 #11 #21 ..)
Read messages in topic with timestamps at least N seconds apart:
--every-nth-interval 5 # (samples topic messages no more often than every 5 seconds)
Conditions
--condition "PYTHON EXPRESSION"
Specify one or more Python expressions that must evaluate as true to search encountered messages. Expressions can access topics, by name or * wildcard, and refer to message fields directly.
# (Match while last message in '/robot/enabled' has data=true)
--condition "<topic /robot/enabled>.data"
# (Match if at least 10 messages have been encountered in /robot/alerts)
--condition "len(<topic /robot/alerts>) > 10"
# (Match if last two messages in /robot/mode have equal .value)
--condition "<topic /robot/mode>[-2].value == <topic /robot/mode>[-1].value"
# (Match while control is enabled and robot is moving straight and level)
--condition "<topic */control_enable>.data and <topic */cmd_vel>.linear.x > 0 " \
"and <topic */cmd_vel>.angular.z < 0.02"
Condition namespace:
| Name | Description |
|---|---|
msg |
current message from data source |
topic |
full name of current message topic |
<topic /my/topic> |
topic by full name or * wildcard |
len(<topic ..>) |
number of messages encountered in topic |
bool(<topic ..>) |
whether any message encountered in topic |
<topic ..>.xyz |
attribute xyz of last message in topic |
<topic ..>[index] |
topic message at position |
| (from first encountered if index >= 0, last encountered if < 0) | |
<topic ..>[index].xyz |
attribute xyz of topic message at position |
value in msg |
whether any field in current message contains value |
value in <topic ..> |
whether any field in last topic message contains value |
value in <topic ..>[index] |
whether any field in topic message at position contains value |
Condition is automatically false if trying to access attributes of a message not yet received.
Plugins
--plugin some.python.module some.other.module.Class
Load one or more Python modules or classes as plugins.
Specifying --plugin someplugin and --help will include plugin options in printed help.
Built-in plugins:
embag
--plugin grepros.plugins.embag
Use the embag library for reading ROS1 bags.
Significantly faster, but library tends to be unstable.
mcap
--plugin grepros.plugins.mcap
Read or write messages in MCAP format.
parquet
--plugin grepros.plugins.parquet \
--write path/to/my.parquet [format=parquet] [overwrite=true|false] \
[column-name=rostype:value] [type-rostype=arrowtype] \
[idgenerator=callable] [nesting=array|all] [writer-argname=argvalue]
Write messages to Apache Parquet files (columnar storage format, version 2.6), each message type to a separate file.
sql
--plugin grepros.plugins.sql \
--write path/to/my.sql [format=sql] [overwrite=true|false] \
[nesting=array|all] [dialect=clickhouse|postgres|sqlite] \
[dialect-file=path/to/dialects.yaml]
Write SQL schema to output file, CREATE TABLE for each message type and CREATE VIEW for each topic.
More on plugins in doc/DETAIL.md.
Notes on ROS1 vs ROS2
In ROS1, message type packages do not need to be installed locally to be able to read messages from bags or live topics, as bags and topic publishers provide message type definition texts, and message classes can be generated at run-time from the type definition text. This is what rosbag does automatically, and so does grepros.
Additionally, each ROS1 message type has a hash code computed from its type definition text, available both in live topic metadata, and bag metadata. The message type definition hash code allows to recognize changes in message type packages and use the correct version of the message type.
ROS2 does not provide message type definitions, neither in the .db3 bagfiles nor in live topics. Due to this, the message type packages always need to be installed. Also, ROS2 does not provide options for generating type classes at run-time, and it does not have the concept of a message type hash.
These are serious limitations in ROS2 compared to ROS1, at least with versions up to ROS2 Humble and counting, and require extra work to smooth over. Without knowing which version of a message type package a bag was recorded with, reading bag messages with changed definitions can result in undefined behaviour.
If the serialized message structure happens to match (e.g. a change swapped
the order of two int32 fields), messages will probably be deserialized
seemingly successfully but with invalid content. If the serialized structure
does not match, the result is a run-time error.
Because of this, it is prudent to always include a snapshot archive of used message type packages, when recording ROS2 bags.
grepros does provide the message type hash itself in ROS2 exports, by calculating the ROS2 message type hash on its own from the locally installed type definition.
The situation in ROS2 with the newer MCAP format is a bit better: at least parsed message data can be read from MCAP bags without needing the specific message packages installed. However, reading from MCAP bags yields only data structs, not usable as ROS messages e.g. for publishing to live topics. grepros tries to smooth over this difference by defaulting to locally installed message classes if available, with definitions matching message types in bag.
All command-line arguments
positional arguments:
PATTERN pattern(s) to find in message field values,
all messages match if not given,
can specify message field as NAME=PATTERN
(supports nested.paths and * wildcards)
optional arguments:
-h, --help show this help message and exit
-F, --fixed-strings PATTERNs are ordinary strings, not regular expressions
-I, --no-ignore-case use case-sensitive matching in PATTERNs
-v, --invert-match select messages not matching PATTERNs
-e, --expression PATTERNs are a logical expression
like 'this AND (this2 OR NOT "skip this")',
with elements as patterns to find in message fields
--version display version information and exit
--live read messages from live ROS topics instead of bagfiles
--publish publish matched messages to live ROS topics
--write TARGET [format=bag|csv|html|mcap|parquet|postgres|sql|sqlite] [KEY=VALUE ...]
write matched messages to specified output,
format is autodetected from TARGET if not specified.
Bag or database will be appended to if it already exists.
Keyword arguments are given to output writer.
column-NAME=ROSTYPE:VALUE
additional column to add in Parquet output,
like column-bag_hash=string:26dfba2c
commit-interval=NUM transaction size for Postgres/SQLite output
(default 1000, 0 is autocommit)
dialect-file=path/to/dialects.yaml
load additional SQL dialect options
for Postgres/SQL/SQLite output
from a YAML or JSON file
dialect=clickhouse|postgres|sqlite
use specified SQL dialect in SQL output
(default "sqlite")
idgenerator=CALLABLE callable or iterable for producing message IDs
in Parquet output, like 'uuid.uuid4' or 'itertools.count()';
nesting uses UUID values by default
message-yaml=true|false whether to populate table field messages.yaml
in SQLite output (default true)
nesting=array|all create tables for nested message types
in Parquet/Postgres/SQL/SQLite output,
only for arrays if "array"
else for any nested types
(array fields in parent will be populated
with foreign keys instead of messages as JSON)
overwrite=true|false overwrite existing file
in bag/CSV/HTML/MCAP/Parquet/SQL/SQLite output
instead of appending to if bag or database
or appending unique counter to file name
(default false)
rollover-count=NUM message limit for individual files
in bag/HTML/MCAP/SQLite output
(supports abbreviations like 1K or 2M or 3G)
rollover-duration=INTERVAL
message time span limit for individual files
in bag/HTML/MCAP/SQLite output
as seconds (supports abbreviations like 60m or 2h or 1d)
rollover-size=NUM size limit for individual files
in bag/HTML/MCAP/SQLite output
as bytes (supports abbreviations like 1K or 2M or 3G)
rollover-template=STR output filename template for individual files
in bag/HTML/MCAP/SQLite output,
supporting strftime format codes like "%H-%M-%S"
and "%(index)s" as output file index
template=/my/path.tpl custom template to use for HTML output
type-ROSTYPE=ARROWTYPE custom mapping between ROS and pyarrow type
for Parquet output, like type-time="timestamp('ns')"
or type-uint8[]="list(uint8())"
writer-ARGNAME=ARGVALUE additional arguments for Parquet output
given to pyarrow.parquet.ParquetWriter
--plugin PLUGIN [PLUGIN ...]
load a Python module or class as plugin
(built-in plugins: grepros.plugins.embag,
grepros.plugins.mcap, grepros.plugins.parquet,
grepros.plugins.sql)
--stop-on-error stop further execution on any error like unknown message type
Filtering:
-t TOPIC [TOPIC ...], --topic TOPIC [TOPIC ...]
ROS topics to read if not all (supports * wildcards)
-nt TOPIC [TOPIC ...], --no-topic TOPIC [TOPIC ...]
ROS topics to skip (supports * wildcards)
-d TYPE [TYPE ...], --type TYPE [TYPE ...]
ROS message types to read if not all (supports * wildcards)
-nd TYPE [TYPE ...], --no-type TYPE [TYPE ...]
ROS message types to skip (supports * wildcards)
--condition CONDITION [CONDITION ...]
extra conditions to require for matching messages,
as ordinary Python expressions, can refer to last messages
in topics as <topic /my/topic>; topic name can contain wildcards.
E.g. --condition "<topic /robot/enabled>.data" matches
messages only while last message in '/robot/enabled' has data=true.
-t0 TIME, --start-time TIME
earliest timestamp of messages to read
as relative seconds if signed,
or epoch timestamp or ISO datetime
(for bag input, relative to bag start time
if positive or end time if negative,
for live input relative to system time,
datetime may be partial like 2021-10-14T12)
-t1 TIME, --end-time TIME
latest timestamp of messages to read
as relative seconds if signed,
or epoch timestamp or ISO datetime
(for bag input, relative to bag start time
if positive or end time if negative,
for live input relative to system time,
datetime may be partial like 2021-10-14T12)
-n0 INDEX, --start-index INDEX
message index within topic to start from
(1-based if positive, counts back from bag total if negative)
-n1 INDEX, --end-index INDEX
message index within topic to stop at
(1-based if positive, counts back from bag total if negative)
--every-nth-message NUM
read every Nth message within topic, starting from first
--every-nth-interval SECONDS
read messages at least N seconds apart within topic
--every-nth-match NUM
emit every Nth match in topic, starting from first
-sf FIELD [FIELD ...], --select-field FIELD [FIELD ...]
message fields to use in matching if not all
(supports nested.paths and * wildcards)
-ns FIELD [FIELD ...], --no-select-field FIELD [FIELD ...]
message fields to skip in matching
(supports nested.paths and * wildcards)
-m NUM, --max-count NUM
number of matched messages to emit (per each file if bag input)
--max-per-topic NUM number of matched messages to emit from each topic
(per each file if bag input)
--max-topics NUM number of topics to emit matches from (per each file if bag input)
--unique-only only emit matches that are unique in topic,
taking --select-field and --no-select-field into account
(per each file if bag input)
Output control:
-B NUM, --before-context NUM
emit NUM messages of leading context before match
-A NUM, --after-context NUM
emit NUM messages of trailing context after match
-C NUM, --context NUM
emit NUM messages of leading and trailing context
around match
-ef FIELD [FIELD ...], --emit-field FIELD [FIELD ...]
message fields to emit in console/CSV/HTML/Parquet output if not all
(supports nested.paths and * wildcards)
-nf FIELD [FIELD ...], --no-emit-field FIELD [FIELD ...]
message fields to skip in console/CSV/HTML/Parquet output
(supports nested.paths and * wildcards)
-mo, --matched-fields-only
emit only the fields where PATTERNs find a match in console/HTML output
-la NUM, --lines-around-match NUM
emit only matched fields and NUM message lines
around match in console/HTML output
-lf NUM, --lines-per-field NUM
maximum number of lines to emit per field in console/HTML output
-l0 NUM, --start-line NUM
message line number to start emitting from in console/HTML output
(1-based if positive, counts back from total if negative)
-l1 NUM, --end-line NUM
message line number to stop emitting at in console/HTML output
(1-based if positive, counts back from total if negative)
-lm NUM, --lines-per-message NUM
maximum number of lines to emit per message in console/HTML output
--match-wrapper [STR [STR ...]]
string to wrap around matched values in console/HTML output,
both sides if one value, start and end if more than one,
or no wrapping if zero values
(default "**" in colorless output)
--wrap-width NUM character width to wrap message YAML console output at,
0 disables (defaults to detected terminal width)
--color {auto,always,never}
use color output in console (default "always")
--no-meta do not print source and message metainfo to console
--no-filename do not print bag filename prefix on each console message line
--no-highlight do not highlight matched values
--no-console-output do not print matches to console
--progress show progress bar when not printing matches to console
--verbose print status messages during console output
for publishing and writing, and error stacktraces
--no-verbose do not print status messages during console output
for publishing and writing
Bag input control:
-n FILE [FILE ...], --filename FILE [FILE ...]
names of ROS bagfiles to read if not all in directory
(supports * wildcards)
-p PATH [PATH ...], --path PATH [PATH ...]
paths to scan if not current directory
(supports * wildcards)
-r, --recursive recurse into subdirectories when looking for bagfiles
--order-bag-by {topic,type}
order bag messages by topic or type first and then by time
--decompress decompress archived bagfiles with recognized extensions (.zst .zstd)
--reindex-if-unindexed
reindex unindexed bagfiles (ROS1 only), makes backup copies
--time-scale [FACTOR]
emit messages on original bag timeline from first matched message,
optionally with a speedup or slowdown factor
Live topic control:
--publish-prefix PREFIX
prefix to prepend to input topic name on publishing match
--publish-suffix SUFFIX
suffix to append to input topic name on publishing match
--publish-fixname TOPIC
single output topic name to publish all matches to,
overrides prefix and suffix
--queue-size-in SIZE live ROS topic subscriber queue size (default 10)
--queue-size-out SIZE
output publisher queue size (default 10)
--ros-time-in use ROS time instead of system time for incoming message
timestamps from subsribed live ROS topics
Dependencies
grepros requires Python 3.8+ or Python 2.7, and the following 3rd-party Python packages:
- pyyaml (https://pypi.org/project/PyYAML)
- six (https://pypi.org/project/six)
- ROS1: rospy, roslib, rosbag, genpy
- ROS2: rclpy, rosidl_parser, rosidl_runtime_py, builtin_interfaces
Optional, for decompressing archived bags:
- zstandard (https://pypi.org/project/zstandard)
Optional, for faster reading of ROS1 bags:
- embag (https://github.com/embarktrucks/embag)
Optional, for Postgres output:
- psycopg2 (https://pypi.org/project/psycopg2)
Optional, for Parquet output:
- pandas (https://pypi.org/project/pandas)
- pyarrow (https://pypi.org/project/pyarrow)
Optional, for MCAP input-output:
- mcap (https://pypi.org/project/mcap)
- mcap_ros1_support (https://pypi.org/project/mcap_ros1_support)
- mcap_ros2_support (https://pypi.org/project/mcap_ros2_support)
Optional, for generating API documentation:
- doxypypy (https://pypi.org/project/doxypypy;
needs latest master:
pip install git+https://github.com/Feneric/doxypypy)
All dependencies other than rospy/rclpy can be installed with:
pip install pyyaml six zstandard embag psycopg2 pandas pyarrow \
mcap mcap_ros1_support mcap_ros2_support \
git+https://github.com/Feneric/doxypypy
Attribution
Includes a modified version of step, Simple Template Engine for Python, (c) 2012, Daniele Mazzocchio, https://github.com/dotpy/step, released under the MIT license.
License
Copyright (c) 2021 by Erki Suurjaak. Released as free open source software under the BSD License, see LICENSE.md for full details.