No version for distro humble. Known supported distros are highlighted in the buttons above.
No version for distro jazzy. Known supported distros are highlighted in the buttons above.
No version for distro rolling. Known supported distros are highlighted in the buttons above.

|
|
Package Summary
| Tags | No category tags. |
| Version | 1.2.17 |
| License | BSD |
| Build type | CATKIN |
| Use | RECOMMENDED |
Repository Summary
| Checkout URI | https://github.com/jsk-ros-pkg/jsk_recognition.git |
| VCS Type | git |
| VCS Version | master |
| Last Updated | 2025-01-07 |
| Dev Status | DEVELOPED |
| CI status | Continuous Integration |
| Released | RELEASED |
| Tags | No category tags. |
| Contributing |
Help Wanted (0)
Good First Issues (0) Pull Requests to Review (0) |
Package Description
The sound_classification package
Additional Links
No additional links.
Maintainers
- Naoya Yamaguchi
Authors
No additional authors.
Sound Classification
ROS package to classify sound stream.
Contents
Setup
-
Install ROS. Available OS:
- Ubuntu 16.04 (?)
- Ubuntu 18.04
- Create workspace
mkdir ~/sound_classification_ws/src -p
cd ~/sound_classification_ws/src
git clone https://github.com/jsk-ros-pkg/jsk_recognition.git
rosdep install --from-paths . --ignore-src -y -r
cd ..
catkin build sound_classification
source ~/sound_classification_ws/devel/setup.bash
- Install other packages.
- cuda and cupy are needed for chainer. See installation guide of JSK
- Using GPU is highly recommended.
Usage
- Check and specify your microphone parameters.
- In particular,
device,n_channel,bitdepthandmic_sampling_rateneed to be known. - The example bash commands to get these params are below:
- In particular,
# For device. In this example, card 0 and device 0, so device:="hw:0,0"
$ arecord -l
\**** List of CAPTURE Hardware Devices ****
card 0: PCH [HDA Intel PCH], device 0: ALC293 Analog [ALC293 Analog]
Subdevices: 1/1
Subdevice #0: subdevice #0
# For n_channel, bitdepth and sample_rate,
# Note that sources means input (e.g. microphone) and sinks means output (e.g. speaker)
$ pactl list short sources
1 alsa_input.pci-0000_00_1f.3.analog-stereo module-alsa-card.c s16le 2ch 44100Hz SUSPENDED
- Pass these params to each launch file as arguments when launching (e.g., `device:=hw:0,0 n_channel:=2 bitdepth:=16 mic_sampling_rate:=44100`).
- If you use `/audio` topic from other computer and do not want to publish `/audio`, set `use_microphone:=false` at each launch file when launching.
- Save environmental noise to
train_data/noise.npy.- By subtracting noise, spectrograms become clear.
- During this script, you must not give any sound to the sensor.
- You should update noise data everytime before sound recognition, because environmental sound differs everytime.
- 30 noise samples are enough.
$ roslaunch sound_classification save_noise.launch
- Publish audio -> spectrum -> spectrogram topics.
- You can set the max/min frequency to be included in the spectrum by
high_cut_freq/low_cut_freqargs inaudio_to_spectrogram.launch. - If
gui:=true, spectrum and spectrogram are visualized.
- You can set the max/min frequency to be included in the spectrum by
$ roslaunch sound_classification audio_to_spectrogram.launch gui:=true
- Here is an example spectrogram at quiet environment.
- Horiozntal axis is time [Hz]
- Vertical axis is frequency [Hz]
|Spectrogram w/o noise subtraction|Spectrogram w/ noise subtraction|
|---|---|
|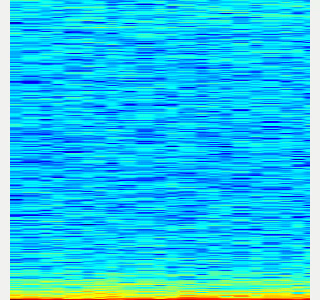|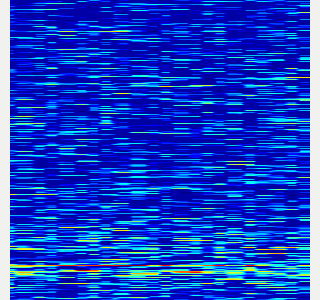|
-
Collect spectrogram you would like to classify.
- When the volume exceeds the
threshold, save the spectrogram attrain_data/original_spectrogram/TARGET_CLASS. - You can use rosbag and stream as sound sources.
- Rosbag version (Recommended)
- I recommend to use rosbag to collect spectrograms. The rosbag makes it easy to use
save_sound.launchwith several parameters. - In
target_class:=TARGET_CLASS, you can set the class name of your target sound. - By using
use_rosbag:=trueandfilename:=PATH_TO_ROSBAG, you can save spectrograms from rosbag. - By default, rosbag is paused at first. Press ‘Space’ key on terminal to start playing rosbag. When rosbag ends, press ‘Ctrl-c’ to terminate.
- The newly saved spectrograms are appended to existing spectrograms.
- You can change threshold of sound saving by
threshold:=xxx. The smaller the value is, the more easily sound is saved.
- I recommend to use rosbag to collect spectrograms. The rosbag makes it easy to use
- When the volume exceeds the
# Save audio to rosbag
$ roslaunch sound_classification record_audio_rosbag.launch filename:=PATH_TO_ROSBAG
# play rosbag and collecting data
$ export ROS_MASTER_URI=http://localhost:11311
$ roslaunch sound_classification save_sound.launch use_rosbag:=true \
filename:=PATH_TO_ROSBAG target_class:=TARGET_CLASS threshold:=0.5
- By setting `threshold:=0` and `save_when_sound:=false`, you can collect spectrogram of "no sound".
# play rosbag and collecting no-sound data
$ export ROS_MASTER_URI=http://localhost:11311
$ roslaunch sound_classification save_sound.launch use_rosbag:=true \
filename:=PATH_TO_ROSBAG target_class:=no_sound threshold:=0 save_when_sound:=false
1. Stream version (Not Recommended)
- You can collect spectrogram directly from audio topic stream.
- Do not use `use_rosbag:=true`. The other args are the same as the rosbag version. Please see above.
$ roslaunch sound_classification save_sound.launch \
save_when_sound:=true target_class:=TARGET_CLASS threshold:=0.5 save_data_rate:=5
- Create dateaset for chainer from saved spectrograms.
- Some data augmentation is executed.
-
--number 30means to use maximum 30 images for each class in dataset.
$ rosrun sound_classification create_dataset.py --number 30
- Visualize dataset.
- You can use
trainarg for train dataset (augmented dataset),testarg for test dataset. - The spectrograms in the dataset are visualized in random order.
- You can use
$ rosrun sound_classification visualize_dataset.py test # train/test
- Train with dataset.
- Default model is
NIN(Recommended). - If you use
vgg16, pretrained weights of VGG16 is downloaded toscripts/VGG_ILSVRC_16_layers.npzat the first time you run this script.
- Default model is
$ rosrun sound_classification train.py --epoch 30
- Classify sounds.
- It takes a few seconds for the neural network weights to be loaded.
-
use_rosbag:=trueandfilename:=PATH_TO_ROSBAGis available if you classify sound with rosbag.
$ roslaunch sound_classification classify_sound.launch
- You can fix class names' color in classification result image by specifying order of class names like below:
<rosparam>
target_names: [none, other, chip_bag]
</rosparam>
- Example classification result:
|no_sound|applause|voice|
|---|---|---|
||||
Quick demo
Sound classification demo with your laptop’s built-in microphone. You can create dataset from rosbag files in sample_rosbag/ directory.
Classification example gif

Commands
$ roslaunch sound_classification save_noise.launch
- Collect spectrograms from sample rosbags. Press ‘Space’ to start rosbag.
- For no_sound class
$ roslaunch sound_classification save_sound.launch use_rosbag:=true \
filename:=$(rospack find sound_classification)/sample_rosbag/no_sound.bag \
target_class:=no_sound threshold:=0 save_when_sound:=false
- For applause class
$ roslaunch sound_classification save_sound.launch use_rosbag:=true \
filename:=$(rospack find sound_classification)/sample_rosbag/applause.bag \
target_class:=applause threshold:=0.5
- For voice class
$ roslaunch sound_classification save_sound.launch use_rosbag:=true \
filename:=$(rospack find sound_classification)/sample_rosbag/voice.bag \
target_class:=voice threshold:=0.5
- Create dataset
$ rosrun sound_classification create_dataset.py --number 30
- Train (takes ~10 minites)
$ rosrun sound_classification train.py --epoch 20
- Classify sound
$ roslaunch sound_classification classify_sound.launch
CHANGELOG
Changelog for package sound_classification
1.2.17 (2023-11-14)
1.2.16 (2023-11-10)
- [audio_to_spectrogram, sound_classification] Add data_to_spectrogram (#2767)
- use catkin_install_python to install python scripts under node_scripts/ scripts/ (#2743)
- [sound_classification] Update setup doc on READMEt( #2732)
- [sound_classification] Enable to pass all arguments of audio_to_spectrogram.launch from upper launches (#2731)
- [sound_classification] Fix pactl option to list up input devices (#2715)
- [sound_classification] set default as python2 in sound_classification (#2698)
- chmod -x sound_classification scripts for catkin_virtualenv (#2659)
- Add sound classification (#2635)
- Contributors: Iori Yanokura, Kei Okada, Naoto Tsukamoto, Naoya Yamaguchi, Shingo Kitagawa, Shun Hasegawa
1.2.15 (2020-10-10)
1.2.14 (2020-10-09)
1.2.13 (2020-10-08)
1.2.12 (2020-10-03)
1.2.11 (2020-10-01)
- add sample program to convert audio message to spectrogram
- [WIP] Add program to classify sound
- Contributors: Naoya Yamaguchi
1.2.10 (2019-03-27)
1.2.9 (2019-02-23)
1.2.8 (2019-02-22)
1.2.7 (2019-02-14)
1.2.6 (2018-11-02)
1.2.5 (2018-04-09)
1.2.4 (2018-01-12)
1.2.3 (2017-11-23)
1.2.2 (2017-07-23)
1.2.1 (2017-07-15 20:44)
1.2.0 (2017-07-15 09:14)
1.1.3 (2017-07-07)
1.1.2 (2017-06-16)
1.1.1 (2017-03-04)
1.1.0 (2017-02-09 22:50)
1.0.4 (2017-02-09 22:48)
1.0.3 (2017-02-08)
1.0.2 (2017-01-12)
1.0.1 (2016-12-13)
1.0.0 (2016-12-12)
0.3.29 (2016-10-30)
0.3.28 (2016-10-29 16:34)
0.3.27 (2016-10-29 00:14)
0.3.26 (2016-10-27)
0.3.25 (2016-09-16)
0.3.24 (2016-09-15)
0.3.23 (2016-09-14)
0.3.22 (2016-09-13)
0.3.21 (2016-04-15)
0.3.20 (2016-04-14)
0.3.19 (2016-03-22)
0.3.18 (2016-03-21)
0.3.17 (2016-03-20)
0.3.16 (2016-02-11)
0.3.15 (2016-02-09)
0.3.14 (2016-02-04)
0.3.13 (2015-12-19 17:35)
0.3.12 (2015-12-19 14:44)
0.3.11 (2015-12-18)
0.3.10 (2015-12-17)
0.3.9 (2015-12-14)
0.3.8 (2015-12-08)
0.3.7 (2015-11-19)
0.3.6 (2015-09-11)
0.3.5 (2015-09-09)
0.3.4 (2015-09-07)
0.3.3 (2015-09-06)
0.3.2 (2015-09-05)
0.3.1 (2015-09-04 17:12)
0.3.0 (2015-09-04 12:37)
0.2.18 (2015-09-04 01:07)
0.2.17 (2015-08-21)
0.2.16 (2015-08-19)
0.2.15 (2015-08-18)
0.2.14 (2015-08-13)
0.2.13 (2015-06-11)
0.2.12 (2015-05-04)
0.2.11 (2015-04-13)
0.2.10 (2015-04-09)
0.2.9 (2015-03-29)
0.2.7 (2015-03-26)
0.2.6 (2015-03-25)
0.2.5 (2015-03-17)
0.2.4 (2015-03-08)
0.2.3 (2015-02-02)
0.2.2 (2015-01-30)
0.2.0 (2015-01-29 12:20)
0.1.34 (2015-01-29 11:53)
0.1.33 (2015-01-24)
0.1.32 (2015-01-12)
0.1.31 (2015-01-08)
0.1.30 (2014-12-24 16:45)
0.1.29 (2014-12-24 12:43)
0.1.28 (2014-12-17)
0.1.27 (2014-12-09)
0.1.26 (2014-11-23)
0.1.25 (2014-11-21)
0.1.24 (2014-11-15)
0.1.23 (2014-10-09)
0.1.22 (2014-09-24)
0.1.21 (2014-09-20)
0.1.20 (2014-09-17)
0.1.19 (2014-09-15)
0.1.18 (2014-09-13)
0.1.17 (2014-09-07)
0.1.16 (2014-09-04)
0.1.15 (2014-08-26)
0.1.14 (2014-08-01)
0.1.13 (2014-07-29)
0.1.12 (2014-07-24)
0.1.11 (2014-07-08)
0.1.10 (2014-07-07)
0.1.9 (2014-07-01)
0.1.8 (2014-06-29)
0.1.7 (2014-05-31)
0.1.6 (2014-05-30)
0.1.5 (2014-05-29)
0.1.4 (2014-04-25)
0.1.3 (2014-04-12)
0.1.2 (2014-04-11)
0.1.1 (2014-04-10)
Wiki Tutorials
This package does not provide any links to tutorials in it's rosindex metadata.
You can check on the ROS Wiki Tutorials page for the package.
Package Dependencies
System Dependencies
No direct system dependencies.
Dependant Packages
No known dependants.
Launch files
- launch/classify_sound.launch
-
- device [default: hw:0,0]
- n_channel [default: 2]
- bitdepth [default: 16]
- mic_sampling_rate [default: 44100]
- use_rosbag [default: false]
- filename [default: /]
- use_microphone [default: true]
- high_cut_freq [default: 8000]
- low_cut_freq [default: 1]
- spectrogram_period [default: 1]
- pause_rosbag [default: true]
- gpu [default: 0]
- gui [default: true]
- launch/record_audio_rosbag.launch
-
- filename
- device [default: hw:0,0]
- n_channel [default: 2]
- bitdepth [default: 16]
- mic_sampling_rate [default: 44100]
- use_microphone [default: true]
- launch/save_noise.launch
-
- device [default: hw:0,0]
- n_channel [default: 2]
- bitdepth [default: 16]
- mic_sampling_rate [default: 44100]
- use_rosbag [default: false]
- filename [default: /]
- use_microphone [default: true]
- high_cut_freq [default: 8000]
- low_cut_freq [default: 1]
- spectrogram_period [default: 1]
- pause_rosbag [default: true]
- gui [default: true]
- save_data_rate [default: 10]
- launch/save_sound.launch
-
- device [default: hw:0,0]
- n_channel [default: 2]
- bitdepth [default: 16]
- mic_sampling_rate [default: 44100]
- use_rosbag [default: false]
- filename [default: /]
- use_microphone [default: true]
- high_cut_freq [default: 8000]
- low_cut_freq [default: 1]
- spectrogram_period [default: 1]
- pause_rosbag [default: true]
- gui [default: true]
- save_data_rate [default: 5]
- target_class [default: ]
- save_when_sound [default: true]
- threshold [default: 0.5]
- launch/audio_to_spectrogram.launch
-
- device [default: hw:0,0]
- n_channel [default: 2]
- bitdepth [default: 16]
- mic_sampling_rate [default: 44100]
- use_rosbag [default: false]
- filename [default: /]
- use_microphone [default: true]
- high_cut_freq [default: 8000]
- low_cut_freq [default: 1]
- spectrogram_period [default: 1]
- gui [default: false]
- pause_rosbag [default: true]
Messages
Services
No service files found
Plugins
No plugins found.
Recent questions tagged sound_classification at Robotics Stack Exchange
No version for distro galactic. Known supported distros are highlighted in the buttons above.
No version for distro iron. Known supported distros are highlighted in the buttons above.
|
|
Package Summary
| Tags | No category tags. |
| Version | 1.2.17 |
| License | BSD |
| Build type | CATKIN |
| Use | RECOMMENDED |
Repository Summary
| Checkout URI | https://github.com/jsk-ros-pkg/jsk_recognition.git |
| VCS Type | git |
| VCS Version | master |
| Last Updated | 2025-01-07 |
| Dev Status | DEVELOPED |
| CI status | No Continuous Integration |
| Released | RELEASED |
| Tags | No category tags. |
| Contributing |
Help Wanted (0)
Good First Issues (0) Pull Requests to Review (0) |
Package Description
The sound_classification package
Additional Links
No additional links.
Maintainers
- Naoya Yamaguchi
Authors
No additional authors.
Sound Classification
ROS package to classify sound stream.
Contents
Setup
-
Install ROS. Available OS:
- Ubuntu 16.04 (?)
- Ubuntu 18.04
- Create workspace
mkdir ~/sound_classification_ws/src -p
cd ~/sound_classification_ws/src
git clone https://github.com/jsk-ros-pkg/jsk_recognition.git
rosdep install --from-paths . --ignore-src -y -r
cd ..
catkin build sound_classification
source ~/sound_classification_ws/devel/setup.bash
- Install other packages.
- cuda and cupy are needed for chainer. See installation guide of JSK
- Using GPU is highly recommended.
Usage
- Check and specify your microphone parameters.
- In particular,
device,n_channel,bitdepthandmic_sampling_rateneed to be known. - The example bash commands to get these params are below:
- In particular,
# For device. In this example, card 0 and device 0, so device:="hw:0,0"
$ arecord -l
\**** List of CAPTURE Hardware Devices ****
card 0: PCH [HDA Intel PCH], device 0: ALC293 Analog [ALC293 Analog]
Subdevices: 1/1
Subdevice #0: subdevice #0
# For n_channel, bitdepth and sample_rate,
# Note that sources means input (e.g. microphone) and sinks means output (e.g. speaker)
$ pactl list short sources
1 alsa_input.pci-0000_00_1f.3.analog-stereo module-alsa-card.c s16le 2ch 44100Hz SUSPENDED
- Pass these params to each launch file as arguments when launching (e.g., `device:=hw:0,0 n_channel:=2 bitdepth:=16 mic_sampling_rate:=44100`).
- If you use `/audio` topic from other computer and do not want to publish `/audio`, set `use_microphone:=false` at each launch file when launching.
- Save environmental noise to
train_data/noise.npy.- By subtracting noise, spectrograms become clear.
- During this script, you must not give any sound to the sensor.
- You should update noise data everytime before sound recognition, because environmental sound differs everytime.
- 30 noise samples are enough.
$ roslaunch sound_classification save_noise.launch
- Publish audio -> spectrum -> spectrogram topics.
- You can set the max/min frequency to be included in the spectrum by
high_cut_freq/low_cut_freqargs inaudio_to_spectrogram.launch. - If
gui:=true, spectrum and spectrogram are visualized.
- You can set the max/min frequency to be included in the spectrum by
$ roslaunch sound_classification audio_to_spectrogram.launch gui:=true
- Here is an example spectrogram at quiet environment.
- Horiozntal axis is time [Hz]
- Vertical axis is frequency [Hz]
|Spectrogram w/o noise subtraction|Spectrogram w/ noise subtraction|
|---|---|
|||
-
Collect spectrogram you would like to classify.
- When the volume exceeds the
threshold, save the spectrogram attrain_data/original_spectrogram/TARGET_CLASS. - You can use rosbag and stream as sound sources.
- Rosbag version (Recommended)
- I recommend to use rosbag to collect spectrograms. The rosbag makes it easy to use
save_sound.launchwith several parameters. - In
target_class:=TARGET_CLASS, you can set the class name of your target sound. - By using
use_rosbag:=trueandfilename:=PATH_TO_ROSBAG, you can save spectrograms from rosbag. - By default, rosbag is paused at first. Press ‘Space’ key on terminal to start playing rosbag. When rosbag ends, press ‘Ctrl-c’ to terminate.
- The newly saved spectrograms are appended to existing spectrograms.
- You can change threshold of sound saving by
threshold:=xxx. The smaller the value is, the more easily sound is saved.
- I recommend to use rosbag to collect spectrograms. The rosbag makes it easy to use
- When the volume exceeds the
# Save audio to rosbag
$ roslaunch sound_classification record_audio_rosbag.launch filename:=PATH_TO_ROSBAG
# play rosbag and collecting data
$ export ROS_MASTER_URI=http://localhost:11311
$ roslaunch sound_classification save_sound.launch use_rosbag:=true \
filename:=PATH_TO_ROSBAG target_class:=TARGET_CLASS threshold:=0.5
- By setting `threshold:=0` and `save_when_sound:=false`, you can collect spectrogram of "no sound".
# play rosbag and collecting no-sound data
$ export ROS_MASTER_URI=http://localhost:11311
$ roslaunch sound_classification save_sound.launch use_rosbag:=true \
filename:=PATH_TO_ROSBAG target_class:=no_sound threshold:=0 save_when_sound:=false
1. Stream version (Not Recommended)
- You can collect spectrogram directly from audio topic stream.
- Do not use `use_rosbag:=true`. The other args are the same as the rosbag version. Please see above.
$ roslaunch sound_classification save_sound.launch \
save_when_sound:=true target_class:=TARGET_CLASS threshold:=0.5 save_data_rate:=5
- Create dateaset for chainer from saved spectrograms.
- Some data augmentation is executed.
-
--number 30means to use maximum 30 images for each class in dataset.
$ rosrun sound_classification create_dataset.py --number 30
- Visualize dataset.
- You can use
trainarg for train dataset (augmented dataset),testarg for test dataset. - The spectrograms in the dataset are visualized in random order.
- You can use
$ rosrun sound_classification visualize_dataset.py test # train/test
- Train with dataset.
- Default model is
NIN(Recommended). - If you use
vgg16, pretrained weights of VGG16 is downloaded toscripts/VGG_ILSVRC_16_layers.npzat the first time you run this script.
- Default model is
$ rosrun sound_classification train.py --epoch 30
- Classify sounds.
- It takes a few seconds for the neural network weights to be loaded.
-
use_rosbag:=trueandfilename:=PATH_TO_ROSBAGis available if you classify sound with rosbag.
$ roslaunch sound_classification classify_sound.launch
- You can fix class names' color in classification result image by specifying order of class names like below:
<rosparam>
target_names: [none, other, chip_bag]
</rosparam>
- Example classification result:
|no_sound|applause|voice|
|---|---|---|
||||
Quick demo
Sound classification demo with your laptop’s built-in microphone. You can create dataset from rosbag files in sample_rosbag/ directory.
Classification example gif
Commands
$ roslaunch sound_classification save_noise.launch
- Collect spectrograms from sample rosbags. Press ‘Space’ to start rosbag.
- For no_sound class
$ roslaunch sound_classification save_sound.launch use_rosbag:=true \
filename:=$(rospack find sound_classification)/sample_rosbag/no_sound.bag \
target_class:=no_sound threshold:=0 save_when_sound:=false
- For applause class
$ roslaunch sound_classification save_sound.launch use_rosbag:=true \
filename:=$(rospack find sound_classification)/sample_rosbag/applause.bag \
target_class:=applause threshold:=0.5
- For voice class
$ roslaunch sound_classification save_sound.launch use_rosbag:=true \
filename:=$(rospack find sound_classification)/sample_rosbag/voice.bag \
target_class:=voice threshold:=0.5
- Create dataset
$ rosrun sound_classification create_dataset.py --number 30
- Train (takes ~10 minites)
$ rosrun sound_classification train.py --epoch 20
- Classify sound
$ roslaunch sound_classification classify_sound.launch
CHANGELOG
Changelog for package sound_classification
1.2.17 (2023-11-14)
1.2.16 (2023-11-10)
- [audio_to_spectrogram, sound_classification] Add data_to_spectrogram (#2767)
- use catkin_install_python to install python scripts under node_scripts/ scripts/ (#2743)
- [sound_classification] Update setup doc on READMEt( #2732)
- [sound_classification] Enable to pass all arguments of audio_to_spectrogram.launch from upper launches (#2731)
- [sound_classification] Fix pactl option to list up input devices (#2715)
- [sound_classification] set default as python2 in sound_classification (#2698)
- chmod -x sound_classification scripts for catkin_virtualenv (#2659)
- Add sound classification (#2635)
- Contributors: Iori Yanokura, Kei Okada, Naoto Tsukamoto, Naoya Yamaguchi, Shingo Kitagawa, Shun Hasegawa
1.2.15 (2020-10-10)
1.2.14 (2020-10-09)
1.2.13 (2020-10-08)
1.2.12 (2020-10-03)
1.2.11 (2020-10-01)
- add sample program to convert audio message to spectrogram
- [WIP] Add program to classify sound
- Contributors: Naoya Yamaguchi
1.2.10 (2019-03-27)
1.2.9 (2019-02-23)
1.2.8 (2019-02-22)
1.2.7 (2019-02-14)
1.2.6 (2018-11-02)
1.2.5 (2018-04-09)
1.2.4 (2018-01-12)
1.2.3 (2017-11-23)
1.2.2 (2017-07-23)
1.2.1 (2017-07-15 20:44)
1.2.0 (2017-07-15 09:14)
1.1.3 (2017-07-07)
1.1.2 (2017-06-16)
1.1.1 (2017-03-04)
1.1.0 (2017-02-09 22:50)
1.0.4 (2017-02-09 22:48)
1.0.3 (2017-02-08)
1.0.2 (2017-01-12)
1.0.1 (2016-12-13)
1.0.0 (2016-12-12)
0.3.29 (2016-10-30)
0.3.28 (2016-10-29 16:34)
0.3.27 (2016-10-29 00:14)
0.3.26 (2016-10-27)
0.3.25 (2016-09-16)
0.3.24 (2016-09-15)
0.3.23 (2016-09-14)
0.3.22 (2016-09-13)
0.3.21 (2016-04-15)
0.3.20 (2016-04-14)
0.3.19 (2016-03-22)
0.3.18 (2016-03-21)
0.3.17 (2016-03-20)
0.3.16 (2016-02-11)
0.3.15 (2016-02-09)
0.3.14 (2016-02-04)
0.3.13 (2015-12-19 17:35)
0.3.12 (2015-12-19 14:44)
0.3.11 (2015-12-18)
0.3.10 (2015-12-17)
0.3.9 (2015-12-14)
0.3.8 (2015-12-08)
0.3.7 (2015-11-19)
0.3.6 (2015-09-11)
0.3.5 (2015-09-09)
0.3.4 (2015-09-07)
0.3.3 (2015-09-06)
0.3.2 (2015-09-05)
0.3.1 (2015-09-04 17:12)
0.3.0 (2015-09-04 12:37)
0.2.18 (2015-09-04 01:07)
0.2.17 (2015-08-21)
0.2.16 (2015-08-19)
0.2.15 (2015-08-18)
0.2.14 (2015-08-13)
0.2.13 (2015-06-11)
0.2.12 (2015-05-04)
0.2.11 (2015-04-13)
0.2.10 (2015-04-09)
0.2.9 (2015-03-29)
0.2.7 (2015-03-26)
0.2.6 (2015-03-25)
0.2.5 (2015-03-17)
0.2.4 (2015-03-08)
0.2.3 (2015-02-02)
0.2.2 (2015-01-30)
0.2.0 (2015-01-29 12:20)
0.1.34 (2015-01-29 11:53)
0.1.33 (2015-01-24)
0.1.32 (2015-01-12)
0.1.31 (2015-01-08)
0.1.30 (2014-12-24 16:45)
0.1.29 (2014-12-24 12:43)
0.1.28 (2014-12-17)
0.1.27 (2014-12-09)
0.1.26 (2014-11-23)
0.1.25 (2014-11-21)
0.1.24 (2014-11-15)
0.1.23 (2014-10-09)
0.1.22 (2014-09-24)
0.1.21 (2014-09-20)
0.1.20 (2014-09-17)
0.1.19 (2014-09-15)
0.1.18 (2014-09-13)
0.1.17 (2014-09-07)
0.1.16 (2014-09-04)
0.1.15 (2014-08-26)
0.1.14 (2014-08-01)
0.1.13 (2014-07-29)
0.1.12 (2014-07-24)
0.1.11 (2014-07-08)
0.1.10 (2014-07-07)
0.1.9 (2014-07-01)
0.1.8 (2014-06-29)
0.1.7 (2014-05-31)
0.1.6 (2014-05-30)
0.1.5 (2014-05-29)
0.1.4 (2014-04-25)
0.1.3 (2014-04-12)
0.1.2 (2014-04-11)
0.1.1 (2014-04-10)
Wiki Tutorials
This package does not provide any links to tutorials in it's rosindex metadata.
You can check on the ROS Wiki Tutorials page for the package.
Package Dependencies
System Dependencies
No direct system dependencies.
Dependant Packages
No known dependants.
Launch files
- launch/classify_sound.launch
-
- device [default: hw:0,0]
- n_channel [default: 2]
- bitdepth [default: 16]
- mic_sampling_rate [default: 44100]
- use_rosbag [default: false]
- filename [default: /]
- use_microphone [default: true]
- high_cut_freq [default: 8000]
- low_cut_freq [default: 1]
- spectrogram_period [default: 1]
- pause_rosbag [default: true]
- gpu [default: 0]
- gui [default: true]
- launch/record_audio_rosbag.launch
-
- filename
- device [default: hw:0,0]
- n_channel [default: 2]
- bitdepth [default: 16]
- mic_sampling_rate [default: 44100]
- use_microphone [default: true]
- launch/save_noise.launch
-
- device [default: hw:0,0]
- n_channel [default: 2]
- bitdepth [default: 16]
- mic_sampling_rate [default: 44100]
- use_rosbag [default: false]
- filename [default: /]
- use_microphone [default: true]
- high_cut_freq [default: 8000]
- low_cut_freq [default: 1]
- spectrogram_period [default: 1]
- pause_rosbag [default: true]
- gui [default: true]
- save_data_rate [default: 10]
- launch/save_sound.launch
-
- device [default: hw:0,0]
- n_channel [default: 2]
- bitdepth [default: 16]
- mic_sampling_rate [default: 44100]
- use_rosbag [default: false]
- filename [default: /]
- use_microphone [default: true]
- high_cut_freq [default: 8000]
- low_cut_freq [default: 1]
- spectrogram_period [default: 1]
- pause_rosbag [default: true]
- gui [default: true]
- save_data_rate [default: 5]
- target_class [default: ]
- save_when_sound [default: true]
- threshold [default: 0.5]
- launch/audio_to_spectrogram.launch
-
- device [default: hw:0,0]
- n_channel [default: 2]
- bitdepth [default: 16]
- mic_sampling_rate [default: 44100]
- use_rosbag [default: false]
- filename [default: /]
- use_microphone [default: true]
- high_cut_freq [default: 8000]
- low_cut_freq [default: 1]
- spectrogram_period [default: 1]
- gui [default: false]
- pause_rosbag [default: true]
Messages
Services
No service files found
Plugins
No plugins found.